SOURCE: Pearson book/class power points.
Essential Idea: Genetic information in DNA can be accurately copied and can be translated to make the proteins needed by the cell.
Nature of science: Obtaining evidence for scientific theories—Meselson and Stahl obtained evidence for the semi-conservative replication of DNA.
Understandings:
• The replication of DNA is semi-conservative and depends on complementary base pairing.
• Helicase unwinds the double helix and separates the two strands by breaking hydrogen bonds.
• DNA polymerase links nucleotides together to form a new strand, using the pre-existing strand as a template.
• Transcription is the synthesis of mRNA copied from the DNA base sequences by RNA polymerase.
• Translation is the synthesis of polypeptides on ribosomes.
• The amino acid sequence of polypeptides is determined by mRNA according to the genetic code.
• Codons of three bases on mRNA correspond to one amino acid in a polypeptide.
• Translation depends on complementary base pairing between codons on mRNA and anticodons on tRNA.
Essential Idea: Genetic information in DNA can be accurately copied and can be translated to make the proteins needed by the cell.
Nature of science: Obtaining evidence for scientific theories—Meselson and Stahl obtained evidence for the semi-conservative replication of DNA.
Understandings:
• The replication of DNA is semi-conservative and depends on complementary base pairing.
• Helicase unwinds the double helix and separates the two strands by breaking hydrogen bonds.
• DNA polymerase links nucleotides together to form a new strand, using the pre-existing strand as a template.
• Transcription is the synthesis of mRNA copied from the DNA base sequences by RNA polymerase.
• Translation is the synthesis of polypeptides on ribosomes.
• The amino acid sequence of polypeptides is determined by mRNA according to the genetic code.
• Codons of three bases on mRNA correspond to one amino acid in a polypeptide.
• Translation depends on complementary base pairing between codons on mRNA and anticodons on tRNA.
DNA REPLICATION
REPLICATION INVOLVES "UNZIPPING"
Cells must prepare for a cell division by doubling the DNA content of the cell in a process called DNA replication. This process doubles the quantity of DNA and also ensures that there is an exact copy of each DNA molecule. In the nucleus of cells are 2 types of molecules :
-Enzymes needed for replication, which include helicase and a group of enzymes collectively called DNA polymerase.
-Free nucleotides, which are nucleotides that are not yet bonded and are found floating freely in the nucleoplasm, some contain adenine, some thymine, some cytosine, and some guanine.
One of the early events of DNA replication is the separation of the double helix into 2 single strands. The helix is held together by the hydrogen bonds between complementary base pairs. The enzyme that initiates this separation into 2 single strands is called helicase. Helicase begins at a point in or at the end of a DNA molecule, and moves one complementary base pair at a time, breaking the hydrogen bonds so the double-stranded DNA molecule becomes 2 separate strands.
The unpaired nucleotides on each of these single strands can now be used as a template to help create 2 double-stranded DNA molecule identical to the original. Some people use the analogy of a zipper for this process. When you pull on a zipper, helicase is like the slide mechanism. The separation of 2 sides of DNA molecule is like the two opened sides of a zipper.
-Enzymes needed for replication, which include helicase and a group of enzymes collectively called DNA polymerase.
-Free nucleotides, which are nucleotides that are not yet bonded and are found floating freely in the nucleoplasm, some contain adenine, some thymine, some cytosine, and some guanine.
One of the early events of DNA replication is the separation of the double helix into 2 single strands. The helix is held together by the hydrogen bonds between complementary base pairs. The enzyme that initiates this separation into 2 single strands is called helicase. Helicase begins at a point in or at the end of a DNA molecule, and moves one complementary base pair at a time, breaking the hydrogen bonds so the double-stranded DNA molecule becomes 2 separate strands.
The unpaired nucleotides on each of these single strands can now be used as a template to help create 2 double-stranded DNA molecule identical to the original. Some people use the analogy of a zipper for this process. When you pull on a zipper, helicase is like the slide mechanism. The separation of 2 sides of DNA molecule is like the two opened sides of a zipper.
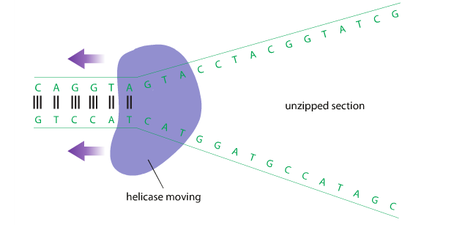
Formation of 2 complementary strands
Once the DNA has become unzipped, the nitrogenous bases on each of the single strands are unpaired. In the environment of the nucleoplasm, are free floating nucleotides. These nucleotides are available to form complementary pairs with the single-stranded nucleotides of the unzipped molecule. A free nucleotide locates on one opened strand at one end, and then a second nucleotide can join the first. This requires these 2 nucleotides to become convalently bonded together, because they are the beginning of a new strand. The formation of a covalent bond between two nucleotides is catalyzed by one of the DNA polymerase enzymes that are important in this process
A third nucleotide then joins the first 2, and the process continues for many nucleotides. The other unzipped strand also acts as a template for the formation of another new strand. This strand forms in the opposite direction to the first strand. In the figure bellow we can see that 1 strand is forming in the same direction as the helicase and the other is replicating in the opposite direction. After the process ends, the 2 old strands are paired with a strand that is new. DNA replication is described as a semi-conservative process because half of a pre-existing DNA molecule is always conserved.
The importance of the DNA replication is that it ensures that 2 identical copies of DNA are produced from one original. DNA replication is described as a semi-conservative process because half of a pre-existing DNA molecule is always conserved.
A third nucleotide then joins the first 2, and the process continues for many nucleotides. The other unzipped strand also acts as a template for the formation of another new strand. This strand forms in the opposite direction to the first strand. In the figure bellow we can see that 1 strand is forming in the same direction as the helicase and the other is replicating in the opposite direction. After the process ends, the 2 old strands are paired with a strand that is new. DNA replication is described as a semi-conservative process because half of a pre-existing DNA molecule is always conserved.
The importance of the DNA replication is that it ensures that 2 identical copies of DNA are produced from one original. DNA replication is described as a semi-conservative process because half of a pre-existing DNA molecule is always conserved.
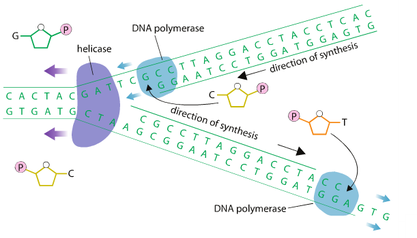
Protein synthesis
The control that DNA has over a cell is determined by a process called protein synthesis. In simple terms, DNA controls the proteins produced in a cell. Some of the proteins produced are enzymes. The production or lack of production of a particular enzyme can have a dramatic effect on the overall biochemistry of the cell. Thus DNA indirectly controls the biochemistry of carbohydrates, lipids and nucleic acids with the production of enzymes.
Protein synthesis involves two processes transcription and translation
VIDEO OF THE PROCESS OF DNA REPLICATION: DNAi_replication_vo1-lg.wm
Protein synthesis involves two processes transcription and translation
VIDEO OF THE PROCESS OF DNA REPLICATION: DNAi_replication_vo1-lg.wm
transcription
Transcription produces RNA molecules
The sections of DNA that code for polypeptides are called genes. Any on gene is a specific sequence of nitrogenous bases found in a specific location of a DNA molecule. Molecules of DNA are found within the confines of the nucleus, yet proteins are synthesized outside the nucleus in the cytoplasm. This means that there has to be an intermediary molecule that carries the message (code) of the DNA to the cytoplasm where the enzymes, ribosome, and amino acids are found. This intermediary molecule is called messenger RNA (mRNA).
The nucleoplasm contains free nucleotides. In addition to the free nucleotides used for DNA replication it contains free RNA nucleotides. Each of these is different form the DNA counterpart, because RNA nucleotides contain a sugar ribose not deoxyribose. Another major difference is that no RNA nucleotides contain thymine, instead they contain Uracil.
The nucleoplasm contains free nucleotides. In addition to the free nucleotides used for DNA replication it contains free RNA nucleotides. Each of these is different form the DNA counterpart, because RNA nucleotides contain a sugar ribose not deoxyribose. Another major difference is that no RNA nucleotides contain thymine, instead they contain Uracil.
the transcription process
The process of transcription begins when an area of DNA of one gene becomes unzipped. This is very similar to the unzipping process involved in DNA replication, but in this case only the area of the DNA where the particular gene is found is unzipped. The 2 complementary strands of DNA are now single stranded in the area of the gene. Recall that RNA is a single stranded molecule, meaning that only one of the 2 strands of DNA will be used as a template to create the mRNA molecule. An enzyme called RNA polymerase is used as a catalyst for this process.
As RNA polymerase moves along the strand of DNA acting as a template, RNa nucelotides float into the place by complementary base pairing rules. The complementary base pairs are the ame as in a double-stranded DNA, with the exception that now A-U is formed in the RNA molecule.
Facts of transcription:
-Only one of the 2 strands of DNA is copied, the other is not used.
-mRNA is always single-stranded and shorter than the DNA that it is copied from, as it is a complementary copy of only one gene.
-The presence of thymine in a molecule identifies it as DNA
-The presence of uracil identifies that it is a RNA molecule.
As RNA polymerase moves along the strand of DNA acting as a template, RNa nucelotides float into the place by complementary base pairing rules. The complementary base pairs are the ame as in a double-stranded DNA, with the exception that now A-U is formed in the RNA molecule.
Facts of transcription:
-Only one of the 2 strands of DNA is copied, the other is not used.
-mRNA is always single-stranded and shorter than the DNA that it is copied from, as it is a complementary copy of only one gene.
-The presence of thymine in a molecule identifies it as DNA
-The presence of uracil identifies that it is a RNA molecule.
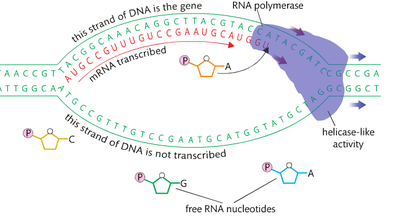
The genetic code is written in triplets
The mRNA molecule produced by transcription represents a complementary copy of one gene of DNA. The sequence of mRNA nucleotides is the transcribed version of the original DNA sequence. This sequence of nucleotides making up the length of the mRNA is typically enough information to make one polypeptide. As you will recall, polypeptides are composed of amino acids covalently bonded together in a specific sequence. The message written into the mRNA molecule is the message that determines the order of the amino acids. Researchers found experimentally that the genetic code is written in a language of three bases. In other words, a set of three bases contains enough information to code for one of the 20 amino acids. Any set of three bases that determines the identity of one amino acid is called a triplet. When a triplet is found in an mRNA molecule, it is also called a codon or codon triplet.
VIDEO OF DNA TRANSCRIPTION: DNAi_transcription_vo1-lg.wmv
VIDEO OF DNA TRANSCRIPTION: DNAi_transcription_vo1-lg.wmv
translation
Translation results in the production of a polypeptide
There are three different kinds of RNA molecule. They are all single-stranded and each is transcribed from a gene (a section of DNA).
Here is a quick summary of each RNA type:
- mRNA, messenger RNA, as described above, each mRNA is a complementary copy of a DNA gene and has enough genetic information to code for a single polypeptide
- rRNA, ribosomal RNA, each ribosome is composed of rRNA and ribosomal protein.
- tRNA, transfer RNA, each type of tRNA transfer one of the 20 amino acids to the ribosome for polypeptide formation.
There are three bases in the middle loop that are called the anticodon bases, and they determine which of the 20 amino acids is attached to the tRNA.
Once an mRNA molecule has been transcribed, the mRNA detaches from the single-strand DNA template and floats free in the nucleoplasm. At some point, the mRNA will float through one of the many holes in the nuclear membrane (nuclear pores) and will then be in the cytoplasm.
Here is a quick summary of each RNA type:
- mRNA, messenger RNA, as described above, each mRNA is a complementary copy of a DNA gene and has enough genetic information to code for a single polypeptide
- rRNA, ribosomal RNA, each ribosome is composed of rRNA and ribosomal protein.
- tRNA, transfer RNA, each type of tRNA transfer one of the 20 amino acids to the ribosome for polypeptide formation.
There are three bases in the middle loop that are called the anticodon bases, and they determine which of the 20 amino acids is attached to the tRNA.
Once an mRNA molecule has been transcribed, the mRNA detaches from the single-strand DNA template and floats free in the nucleoplasm. At some point, the mRNA will float through one of the many holes in the nuclear membrane (nuclear pores) and will then be in the cytoplasm.
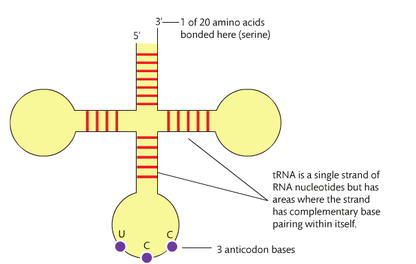
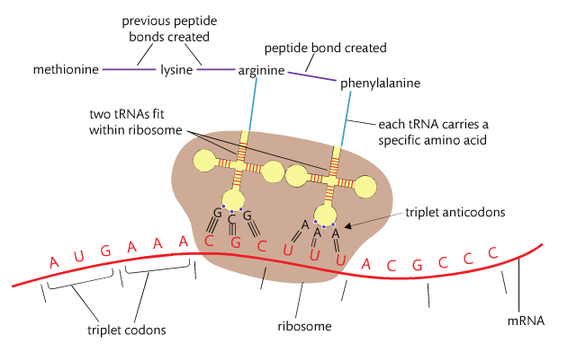
the translation process
The mRNA will locate a ribosome and align with it, so that the first two codon triplets are within the boundaries of the ribosome.
A specific tRNA molecule now floats in: its tRNA anticodon must be complementary to the first codon triplet of the mRNA molecule. Thus the first amino acid is brought into the translation process. It is not just any amino acid; its identity was originally determined by the strand of DNA that transcribed the mRNA being translated. While the first tRNA ‘sits’ in the ribosome holding the first amino acid, a second tRNA floats in and brings a second (again specific) amino acid. The second tRNA matches its three anticodon bases with the second codon triplet of the mRNA. At the end, two specific amino acids are now being held side by side. An enzyme then catalyses a condensation reaction between the two amino acids, and the resulting covalent bond between them is called a peptide bond.
The next step in the translation process involves breaking the bond between the first tRNA molecule and the amino acid that it transferred in. This bond is no longer needed, as the second tRNA is currently bonded to its own amino acid, and that amino acid is covalently bonded to the first amino acid. The first tRNA floats away into the cytoplasm and invariably reloads with another amino acid of the same type. The ribosome that has only one tRNA in it now moves one codon triplet down the mRNA molecule. This, in effect, puts the second tRNA in the ribosome position that the first originally occupied, and creates room for a third tRNA to float in, bringing with it third specific amino acid. The process now becomes repetitive and forms a peptide bond, the ribosomes moves on by another triplet and so on until the last codon triplet, which does not act as a code for an amino acid, instead it signals "stop" to the process of translation. The entire polypeptide breaks away from the final tRNA molecule, and becomes a free-floating polypeptide in the cytoplasm of the cell.
VIDEO OF DNA TRANSLATION: DNAi_translation_vo1-lg.wmv
A specific tRNA molecule now floats in: its tRNA anticodon must be complementary to the first codon triplet of the mRNA molecule. Thus the first amino acid is brought into the translation process. It is not just any amino acid; its identity was originally determined by the strand of DNA that transcribed the mRNA being translated. While the first tRNA ‘sits’ in the ribosome holding the first amino acid, a second tRNA floats in and brings a second (again specific) amino acid. The second tRNA matches its three anticodon bases with the second codon triplet of the mRNA. At the end, two specific amino acids are now being held side by side. An enzyme then catalyses a condensation reaction between the two amino acids, and the resulting covalent bond between them is called a peptide bond.
The next step in the translation process involves breaking the bond between the first tRNA molecule and the amino acid that it transferred in. This bond is no longer needed, as the second tRNA is currently bonded to its own amino acid, and that amino acid is covalently bonded to the first amino acid. The first tRNA floats away into the cytoplasm and invariably reloads with another amino acid of the same type. The ribosome that has only one tRNA in it now moves one codon triplet down the mRNA molecule. This, in effect, puts the second tRNA in the ribosome position that the first originally occupied, and creates room for a third tRNA to float in, bringing with it third specific amino acid. The process now becomes repetitive and forms a peptide bond, the ribosomes moves on by another triplet and so on until the last codon triplet, which does not act as a code for an amino acid, instead it signals "stop" to the process of translation. The entire polypeptide breaks away from the final tRNA molecule, and becomes a free-floating polypeptide in the cytoplasm of the cell.
VIDEO OF DNA TRANSLATION: DNAi_translation_vo1-lg.wmv
Applications and skills:
•Application: Use of Taq DNA polymerase to produce multiple copies of DNA rapidly by the polymerase chain reaction (PCR). •Application: Production of human insulin in bacteria as an example of the universality of the genetic code allowing gene transfer between species.
• Skill: Use a table of the genetic code to deduce which codon(s) corresponds
•Skill: Analysis of Meselson and Stahl’s results to obtain support for the theory of semi-conservative replication of DNA.
• Skill: Use a table of mRNA codons and their corresponding amino acids to deduce the sequence of amino acids coded by a short mRNA strand of known base sequence.
• Skill: Deducing the DNA base sequence for the mRNA strand.
Guidance:
• The different types of DNA polymerase do not need to be distinguished.
•Application: Use of Taq DNA polymerase to produce multiple copies of DNA rapidly by the polymerase chain reaction (PCR). •Application: Production of human insulin in bacteria as an example of the universality of the genetic code allowing gene transfer between species.
• Skill: Use a table of the genetic code to deduce which codon(s) corresponds
•Skill: Analysis of Meselson and Stahl’s results to obtain support for the theory of semi-conservative replication of DNA.
• Skill: Use a table of mRNA codons and their corresponding amino acids to deduce the sequence of amino acids coded by a short mRNA strand of known base sequence.
• Skill: Deducing the DNA base sequence for the mRNA strand.
Guidance:
• The different types of DNA polymerase do not need to be distinguished.
